

K-Nearest Neighbors è una tecnica e un algoritmo di apprendimento automatico che possono essere utilizzati sia per attività di regressione che di classificazione . K-Nearest Neighbors esamina le etichette di un numero scelto di punti dati che circondano un punto dati target, al fine di fare una previsione sulla classe in cui il punto dati rientra. K-Nearest Neighbors (KNN) è un algoritmo concettualmente semplice ma molto potente e, per questi motivi, è uno degli algoritmi di apprendimento automatico più popolari. Facciamo un tuffo profondo nell’algoritmo KNN e vediamo esattamente come funziona. Avere una buona conoscenza del funzionamento di KNN ti consentirà di apprezzare i casi d’uso migliori e peggiori per KNN.
Panoramica di K-Nearest Neighbors (KNN)
Visualizziamo un set di dati su un piano 2D. Immagina un gruppo di punti dati su un grafico, distribuiti lungo il grafico in piccoli gruppi. KNN esamina la distribuzione dei punti dati e, a seconda degli argomenti forniti al modello, separa i punti dati in gruppi. A questi gruppi viene quindi assegnata un’etichetta. Il presupposto principale che fa un modello KNN è che i punti / istanze di dati che esistono in stretta vicinanza tra loro sono molto simili, mentre se un punto di dati è lontano da un altro gruppo è dissimile da quei punti di dati.
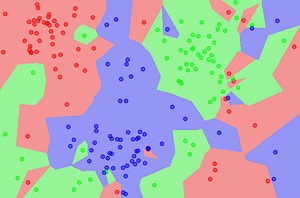
Un modello KNN calcola la somiglianza utilizzando la distanza tra due punti su un grafico. Maggiore è la distanza tra i punti, meno simili sono. Esistono diversi modi per calcolare la distanza tra i punti, ma la metrica della distanza più comune è solo la distanza euclidea (la distanza tra due punti in linea retta).
KNN è un algoritmo di apprendimento supervisionato , il che significa che agli esempi nel set di dati devono essere assegnate etichette / le loro classi devono essere note. Ci sono altre due cose importanti da sapere su KNN. Innanzitutto, KNN è un algoritmo non parametrico. Ciò significa che non vengono fatte supposizioni sul set di dati quando viene utilizzato il modello. Piuttosto, il modello è costruito interamente dai dati forniti. In secondo luogo, non vi è alcuna suddivisione del set di dati in set di addestramento e set di test quando si utilizza KNN. KNN non fa generalizzazioni tra un set di addestramento e un set di test, quindi tutti i dati di addestramento vengono utilizzati anche quando viene chiesto al modello di fare previsioni.
Come funziona un algoritmo KNN
Un algoritmo KNN attraversa tre fasi principali durante la sua esecuzione:
- Impostare K sul numero di vicini scelto.
- Calcolo della distanza tra un esempio fornito / di prova e gli esempi del set di dati.
- Ordinamento delle distanze calcolate.
- Ottenere le etichette delle prime K voci.
- Restituzione di una previsione sull’esempio di test.
Nella prima fase, K viene scelto dall’utente e indica all’algoritmo quanti vicini (quanti punti dati circostanti) dovrebbero essere considerati quando si esprime un giudizio sul gruppo a cui appartiene l’esempio di destinazione. Nella seconda fase, si noti che il modello controlla la distanza tra l’esempio di destinazione e ogni esempio nel set di dati. Le distanze vengono quindi aggiunte in un elenco e ordinate. Successivamente, l’elenco ordinato viene controllato e vengono restituite le etichette per i primi K elementi. In altre parole, se K è impostato su 5, il modello controlla le etichette dei primi 5 punti dati più vicini al punto dati di destinazione. Quando si esegue il rendering di una previsione sul punto dati di destinazione, è importante se l’attività è una regressione o una classificazionecompito. Per un’attività di regressione, viene utilizzata la media delle prime K etichette, mentre la modalità delle prime K etichette viene utilizzata nel caso della classificazione.
Le esatte operazioni matematiche utilizzate per eseguire KNN differiscono a seconda della metrica di distanza scelta. Se desideri saperne di più su come vengono calcolate le metriche, puoi leggere alcune delle metriche di distanza più comuni, come Euclidea , Manhattan e Minkowski .
Perché il valore di K. è importante
La principale limitazione quando si utilizza KNN è che in un valore improprio di K (il numero sbagliato di vicini da considerare) potrebbe essere scelto. In tal caso, le previsioni restituite possono essere sostanzialmente disattivate. È molto importante che, quando si utilizza un algoritmo KNN, venga scelto il valore appropriato per K. Si desidera scegliere un valore per K che massimizzi la capacità del modello di fare previsioni su dati invisibili riducendo il numero di errori che fa.
Valori più bassi di K significano che le previsioni rese dal KNN sono meno stabili e affidabili. Per avere un’idea del motivo per cui è così, considera un caso in cui abbiamo 7 vicini intorno a un punto dati di destinazione. Supponiamo che il modello KNN stia funzionando con un valore K di 2 (gli chiediamo di guardare i due vicini più vicini per fare una previsione). Se la stragrande maggioranza dei vicini (cinque su sette) appartiene alla classe Blu, ma i due vicini più vicini sono semplicemente Rossi, il modello predice che l’esempio di query è Rosso. Nonostante l’ipotesi del modello, in uno scenario del genere il blu sarebbe un’ipotesi migliore.
Se questo è il caso, perché non scegliere semplicemente il valore K più alto possibile? Questo perché dire al modello di considerare troppi vicini ridurrà anche la precisione. Man mano che il raggio che il modello KNN considera aumenta, alla fine inizierà a considerare i punti dati più vicini ad altri gruppi di quanto non siano il punto dati di destinazione e inizierà a verificarsi una classificazione errata. Ad esempio, anche se il punto inizialmente scelto si trovava in una delle regioni rosse sopra, se K fosse impostato troppo alto, il modello raggiungerebbe le altre regioni per considerare i punti. Quando si utilizza un modello KNN, vengono provati diversi valori di K per vedere quale valore offre al modello le migliori prestazioni.
Pro e contro di KNN
Esaminiamo alcuni dei pro e dei contro del modello KNN.
Pro:
- KNN può essere utilizzato sia per attività di regressione che di classificazione, a differenza di altri algoritmi di apprendimento supervisionato.
- KNN è estremamente preciso e semplice da usare. È facile da interpretare, capire e implementare.
- KNN non fa alcuna supposizione sui dati, il che significa che può essere utilizzato per un’ampia varietà di problemi.
Contro:
- KNN memorizza la maggior parte o tutti i dati, il che significa che il modello richiede molta memoria ed è costoso in termini di calcolo. Set di dati di grandi dimensioni possono anche far sì che le previsioni richiedano molto tempo.
- KNN dimostra di essere molto sensibile alla scala del set di dati e può essere scartato da caratteristiche irrilevanti abbastanza facilmente rispetto ad altri modelli.
Riepilogo di K-Nearest Neighbors (KNN)
K-Nearest Neighbors è uno dei più semplici algoritmi di apprendimento automatico. Nonostante quanto sia semplice KNN, in teoria, è anche un potente algoritmo che fornisce una precisione abbastanza elevata sulla maggior parte dei problemi. Quando usi KNN, assicurati di sperimentare vari valori di K per trovare il numero che fornisce la massima precisione.

