Overfitting occurs when a model tries to predict a trend in the data that is too loud. This is due to an overly complex model with too many parameters. An oversized model is inaccurate because the trend does not reflect the reality in the data. This can be judged if the model produces good results on the seen data (training set) but performs poorly on the unseen data (test set). The goal of a machine learning model is to generalize well from the training data to all data from the problem domain. This is very important as we want our model to make future predictions on data it has never seen before.
These are the main methods of reducing overfitting.
Simplify the model
The first step when dealing with overfitting is to decrease the complexity of the model. To decrease complexity, we can simply remove the layers or reduce the number of neurons to make the network smaller. While doing this, it is important to calculate the input and output sizes of the various layers involved in the neural network. There is no general rule of thumb on how much to remove or how large your network should be. But if your neural network is too good, try shrinking it.
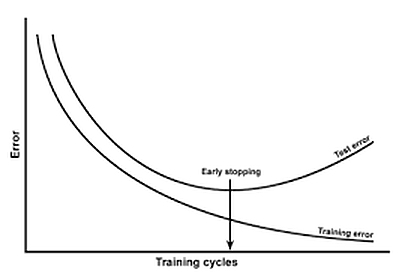
Early stopping
Early stopping is a form of regularization when training a model with an iterative method, such as gradient descent. Since all neural networks learn exclusively using gradient descent, early stopping is a technique applicable to all problems. This method updates the model to better fit the training data at each iteration. To some extent, this improves the performance of the model on the data on the test set. Beyond that point, however, improving the fit of the model to the training data leads to a greater generalization error. Early stopping rules provide guidance on how many iterations can be performed before the model begins to over-fit.
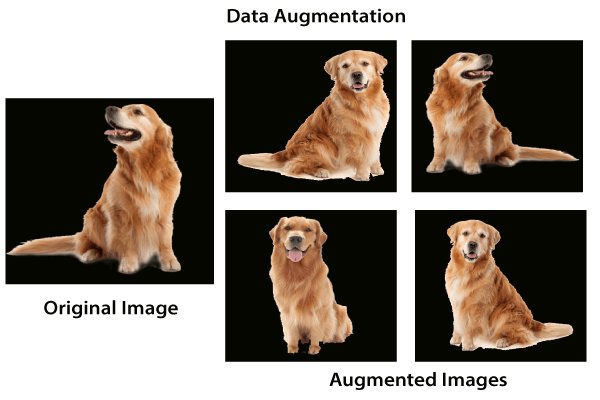
Data augmentation
In the case of neural networks, increasing data simply means increasing the size of the data which is increasing the number of images in the data set. Some of the popular techniques for image enhancement are flipping, translating, rotating, resizing, changing brightness, adding noise etc. For a more complete reference, feel free to check out documentations and imgaug.
Regularization L1 and L2
Regularization is a technique for reducing the complexity of the model. It does this by adding a penalty term to the loss function. The most common techniques are known as L1 and L2 regularization:
The L1 penalty aims to minimize the absolute value of the weights.
The L2 penalty aims to minimize the squared width of the weights.
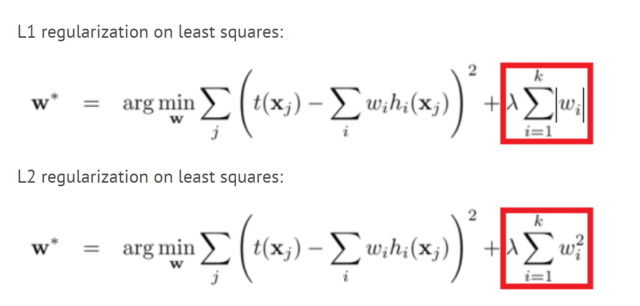
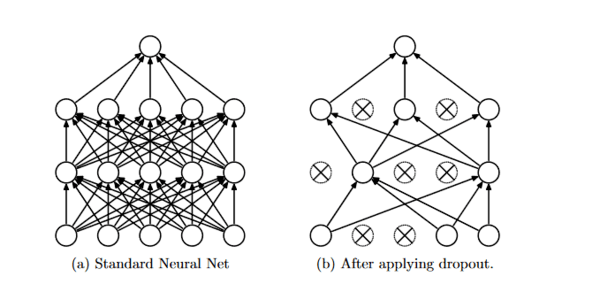
Dropout
Dropout is a regularization technique that prevents overfitting of neural networks. Regularization methods such as L1 and L2 reduce overfitting by modifying the cost function. Dropout on the other hand, changes the network itself. Randomly release neurons from the neural network during training in each iteration. When we release different sets of neurons, it is equivalent to training different neural networks. Different networks adapt in different ways, so the net effect of abandoning will be to reduce overfitting.